Как посмотреть сайт которого уже нет – Как посмотреть сайт, которого уже нет
Как просматривать сайты, которые уже закрылись
Сайты чем-то похожи на людей. Как и люди, они рождаются, развиваются и умирают. Одни скоропостижно, другие — после долгого периода забвения. А ещё они бывают временно недоступны. Также сайты могут обновляться. При этом иногда старые, потерявшие актуальность материалы, удаляются администратором. Последнее можно сравнить с потерей памяти у людей. Однако же, «потеряв память» или отдав концы, сайты не умирают насовсем.
Удивительно, но доступ к большинству веб-ресурсов можно получить даже спустя много лет после их закрытия.
А всё благодаря Archive.org — универсальному архиву Интернета, в задачу которого входит сохранение веб-страниц и цифровых материалов с целью обеспечения к ним свободного доступа историкам, исследователям и просто любопытным пользователям. Библиотека Archive.org хранит не только страницы уже закрытых, но и существующих сайтов, а вернее — их кэшированные копии, соответствующие тому или иному периоду времени.
Также в этом архиве можно найти старые видео, аудио, игры и программное обеспечение, но это уже отдельный разговор. Сейчас же речь идёт исключительно о сайтах. Пользоваться Archive.org очень просто. Всё, что вам нужно знать, так это адрес страницы или сайта, который собираетесь вытащить на свет божий. Разумеется, почившие сайты не обновляются, более того, их функционал может оказаться урезанным.

Для примера давайте попробуем извлечь из небытия закрывшийся в 2012 году варезный сайт FilesHouse.com. Для этого на страничке web.archive.org/web вбиваем адрес сайта и выполняем переход. В результате попадаем на страницу-календарь с выделенными синим маркером днями.

Так отмечаются даты, когда страницы были кэшированы системой архива. Останется только кликнуть по одному из таких маркеров, и можно будет просматривать снапшоты сайта. Стили, скрипты и прочие интерактивные элементы обычно удаляются, но текстовый контент, как правило, доступен всегда, но это только в том случае, если в архиве будет сохранён сам сайт. Веб-архив уступает мощностью поисковикам, поэтому нельзя исключать, что некоторые сайты просто не успеют попасть в его базу.
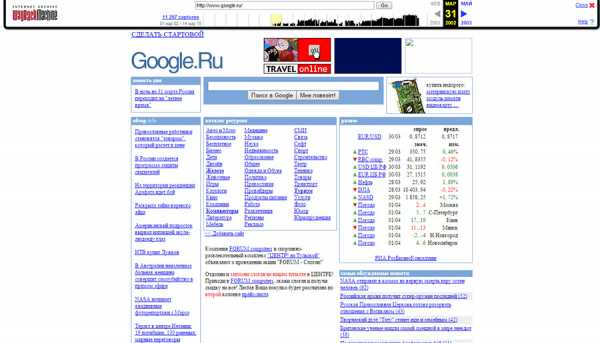
С таким же успехом Archive.org можно использовать для просмотра старых версий вполне здравствующих сайтов, например, вы можете узнать, как выглядела главная страница Google в далёком 2002 году. Вот всё так просто. Что же касается преимуществ Archive.org перед кэшем Google или Яндекса, то тут и так всё понятно — обе эти поисковые системы позволяют получать доступ только к самой последней версии сохранённых копий.
Достаём потерянные статьи из сетевых хранилищ / Habr
Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter — комментарий habrahabr.ru/post/146070/#comment_4914947.
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш archive.org
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
Да и цель сайта — запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Yahoo Pipes
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 и прочие.
Довольно интересное решение. Те, кто умеет их настраивать, возможно, полноценно решат задачу архивирования RSS. Из имеющегося, я не нашёл пайпов с поиском статьи по её номеру, поэтому пока нет прямой ссылки на такие сохранённые полные статьи. (Кто умеет с ним работать — прошу изготовить такую ссылку для скрипта.)
Многочисленные клонировщики
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так: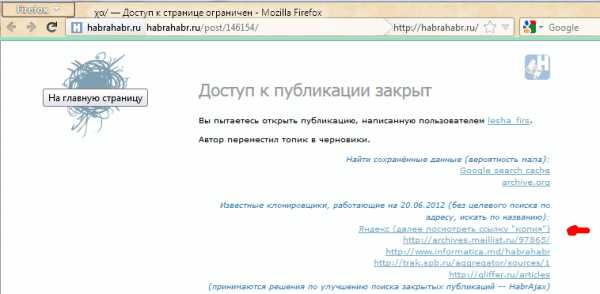
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):
Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):
Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD 23:00: опытным путём для mail.ru было выяснено строение прямой ссылки на кеш:
'http://hl.mailru.su/gcached?q=cache:'+ window.location
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.
habr.com
Как посмотреть старую версию сайта одним классным способом?
Всем привет! Скажите, хотел бы вы ненадолго вернуться в прошлое, чтобы увидеть себя молодого или маленького со стороны, пообщаться, глянуть, каким вы были? К сожалению, такое совершить пока невозможно. Но зато такое можно проделать с любым веб-ресурсом. Я имею в виду, что можно вернуться на год или два назад, чтобы увидеть как выглядел cайт раньше, какой у него был дизайн, даже какая стояла реклама.
Да. Оказывается есть специальный сервис, который несколько десятков раз в году (10-20-100) делает архивные копии сaйтов, и любой желающий может абсолютно бесплатно посмотреть прошлые версии своих или чужих ресурсов. На самом деле это очень крутая вещь, поэтому я настоятельно рекомендую вам окунуться в прошлое. Поэтому сегодня я вам покажу, как посмотреть старую версию сайта одним очень классным и проверенным способом.
Archive.org
Заходите на сайт Archive.org и впишите в специальное поле адрес вашего сайта.

После этого вы увидите годовую ленту и календарь с отмеченными датами. Перемещаясь по ленте, вы выбираете год, в который вы хотите вернуться, и уже для каждого года активируется свой календарь с отмеченными датами. Именно в эти числа была создана архивная копия, а значит вы можете посмотреть состояние на тот момент. Нажмите на любое число, отмеченное кружком. Я наведу на 15 марта 2016 года и тут же появится вставка со временем. Жмите на нее.
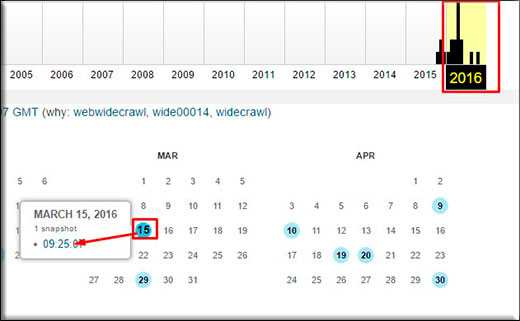
Конечно мой сайт не сильно изменился за последний год, но на 15 марта 2016 года из нет. То есть я не наблюдаю баннеров в правом сайдбаре, не наблюдаю некоторые рубрики, например «Эксперименты» или Заработок и финансы». Также слегка изменено меню, топ комментаторов стал таким, каким был на тот момент, т.е. еще до того, как я исключил себя из этого топа. Правда некоторые моменты отображаются неправильно, например некоторые комментаторы или виджет вконтакте.
Но в целом вещь очень крутая. Можно не просто посмотреть, но и походить по местам былой славы. Действительно, как будто попали в прошлое, а не смотрите фильм про прошлое.
Но у меня дизайн не менялся, поэтому давайте усложним задачу. Возьмем какой-нибудь блог, который существует давно и 100% менял свой дизайн. Я помню, что не так давно моя знакомая по школе блоггеров Настя Скореева поменяла внешний вид своего сайта nyaskory.ru. Сейчас он выглядит так.
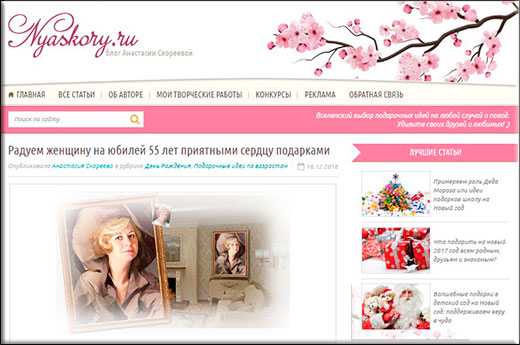
Теперь я иду на наш сервис чтобы проверить старую версию ее блога. Для этого я снова вбиваю имя сайта, выбираю дату, когда еще шаблон был старый, например март 2015 года и вуаля! Смотрим результат. Да. Видно, что блог Насти претерпел большие изменения.

Вконтакте
Ради прикола я еще решил проверить социальную сеть вконтакте и посмотреть предыдущие версии этого сайта. Все мы помним, что сеть начала свою деятельность еще в 2006 году и тогда сайт располагался по адресу vkontakte.ru, а не vk.com. Вот его я и решил ввести и посмотреть его в 2006 году. Вы помните такой дизайн? Вот таким он был.

Я зарегистрировался в 2007 году (помню, как даже смотрел дату регистрации в вк) и вот так выглядел тогда этот сайт.
В 2011 году ВК ограничил свободные регистрации в связи с наплывом фейковых страниц. Зарегистрироваться там просто так было нельзя. Нужно было получить приглашение от зарегистрированного пользователя. И вот тогда главная страница смотрелась так.

А с 2012 года сайт переходит на новый домен vk.com, и со старого происходит автоматическая переадресация. Поэтому с этого момента у вас не получится посмотреть, как выглядел vkontakte.ru например в 2013 году, так как надо вводить уже современный адрес и смотреть там.

В общем как-то так. Здорово, да? Я вот прошелся по старым дизайна вконтакте, и аж ностальгия взяла. Когда я регистрировался, там находилось всего чуть более миллиона человек. А теперь там сотни миллионов.
Ну в общем рекомендую вам тоже пройтись по задворкам прошлого и взглянуть, как всё выглядело раньше. А на сегодня я уже буду закругляться. Надеюсь, что статья была для вас интересной, поэтому не забудьте подписаться на обновления моего блога. С нетерпением буду вас снова ждать у себя в гостях. Удачи вам. Пока-пока!
С уважением, Дмитрий Костин.
koskomp.ru
как найти удаленную из Сети информацию
Интернет – вещь абсолютно не постоянная. Любой сайт в силу различных обстоятельств (обрывы линий электропередач, банкротство хостера, неоплата домена) может перестать работать. В браузерах пользователей после этого отобразятся только сообщения о недоступности любимого ресурса. Если же сайт изменится до неузнаваемости, а страницу с важной информацией удалит администрация, ресурс продолжит свою работу, но конечному потребителю неприятностей в этом случае не избежать.
Не стоит волноваться и проклинать злой рок. Быть может, портал недоступен временно, а специалисты заняты восстановлением его работы. Помимо этого, у каждого пользователя Глобальной сети есть мощный инструмент, который позволит получить необходимую информацию, – кэш сайтов.
Google – мегакорпорация, мощности серверов которой имеют возможность постоянно сканировать Интернет на предмет появления новых страниц и изменения старых. Добавляя ресурсы в свою базу, алгоритмы не только индексируют сайты, но и делают их снимки. Грубо говоря, Google создает резервные копии Интернета на тот случай, если исходный материал станет недоступным.
Кэш сайтов Google доступен всем без исключения. Чтобы получить доступ к любой проиндексированной странице, в строку поисковика требуется ввести запрос: [cashe:http://полная ссылка на страницу]. На экране отобразится копия страницы, в верхней части экрана будет показана следующая информация:
- Дата последнего сохранения, что даст возможность судить, могла ли измениться представленная информация.
- Здесь же располагается ссылка на снимок, в котором содержится только текст.
- Еще один URL покажет полный исходный код, который заинтересует веб-мастеров.
Владельцам ресурсов в Интернете нужно знать, что кэш сайтов компании Google – добровольная в использовании система. Если необходимо исключить какие-либо страницы вашего портала из списка сохраненных, можно запретить делать снимки. Для этого на страницу нужно добавить метатег <meta content=»noarchive»>. Также запретить или разрешить кэширование можно в рабочем кабинете, если вы имеете соответствующий аккаунт.
Если же вам нужно удалить уже сохраненные снимки из кэша Google, потребуется отправить электронное письмо с запросом, а потом подтвердить свои права на сайт.
«Яндекс»
На втором месте в списке компаний, сохраняющих кэш сайтов, располагается отечественный гигант индустрии. Охват «Яндекса» намного меньше, поэтому здесь стоит искать в основном снимки крупных, обладающих высокой посещаемостью ресурсов.
Просто введите в поисковую строку URL нужной страницы и нажмите ENTER. Результаты поиска покажут необходимый вам сайт на первом месте выдачи. Рядом со ссылкой на него будет располагаться иконка в виде треугольника. Кликнув на нее и выбрав пункт меню «сохраненная копия», откроете последний доступный снимок страницы.
The Wayback Machine
В 1996 году Брюстер Кейл открыл некоммерческую организацию, которую сейчас называют архивом Интернета. Компания занимается сбором копий веб-страниц, видеоматериалов, графических изображений, аудиозаписей, программного обспечения. Собранный материал архивируется, а бесплатный доступ к нему может получить любой желающий.
Главная цель The Wayback Machine – сохранение культурных ценностей, созданных цивилизацией после широкого распространения Интернета, создание наиболее полной электронной библиотеки человечества. В настоящий момент в Архиве хранится более 10 петабайт данных, что позволяет пользователям ознакомиться с 85 миллиардами веб-страниц. Это значит, Архив – наиболее полный кэш сайтов.

Archive.org – сайт организации, на нем можно попытаться найти снимок необходимой страницы. Так как сохраняется не только последняя копия, а бот просматривает ресурсы периодически, можно изучить все изменения, сделанные на определенной странице с течением времени, даже если сайт уже не существует. В строке поиска желательно использовать префикс WWW.
Dead URL

«Мертвый адрес» предоставляет для пользователей похожие возможности. Скопируйте из адресной строки нерабочий URL и вставьте его в поле ввода на сайте. Сервис немного подумает и выдаст несколько результатов. Некоторые из них будут ссылаться на ресурс компании Google. Другая часть приведет пользователя на страницы Архива. Что немаловажно, сортируется кэш сайтов по дате, а это очень удобно.
Down Or Not
Если вам необходим кэш сайтов в Интернете в связи с недоступностью того или иного ресурса, но поиски ни к чему не приводят, стоит проверить, не рядом ли с вами проблема. Например, провайдер Интернета выполняет технические работы или заменяет устаревшее оборудование. Для проверки, кто виноват, есть смысл воспользоваться сервисом Down Or Not (Жив или нет).

Введите адрес необходимого вам портала в строку поиска и нажмите на кнопку ENTER. После недолгого анализа сервис выдаст результат. Слово DOWN указывает на недоступность ресурса (временную или постоянную), если же на экране появится слово UP — значит, с порталом всё в порядке.
Down Ot Not выступает в роли стороннего и непредвзятого эксперта, чтобы определить, что именно является источником проблемы.
fb.ru
8 способов найти удаленный сайт или страницу
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com.
Источник: iphones.ru
internetua.com
Как найти в кеше Гугла и Яндекса определенную страницу
Слово кэш можно услышать довольно часто в разных сферах ИТ, сегодня же мы будем разбираться с кэшем страниц сайта. Сам термин означает сохранение поисковыми системами копий страниц от определенного числа, как правило от последнего посещения роботом сайта. Вы можете в любой момент найти и использовать копию (кэш) страницы для своих потребностей.
Это довольно таки хорошо, что поисковики сохраняют на некоторое время страницы на своих серверах и дают нам шанс воспользоваться этим. На хранение кэшированных страниц выделяется много ресурсов и денег, но свою помощь они окупают, так как нам все равно необходимо заходить на их поисковые системы.
К содержанию ↑Для чего нужен кэш (копии) страниц
Бывают разные ситуации при работе с сайтами.
Как всегда работы у Вас много, а времени мало и внимательности на все не хватает. Бывают случаи, когда ведутся работы с сайтом, предположим изменение дизайна или мелкие правки по шаблону, тексту. И в один момент понимаете, что где-то допустили ошибку и пропал текст или исчезла часть дизайна сайта. Ну бывает такое и каждый наверное с таким имел дело.
На данный момент, бэкапов у Вас нету, у хостинга тоже и не помните как выглядело все изначально. В этом случае помочь сможет копия страницы, которую можно найти в кэше как Яндекса, так и в Гугла, посмотреть как было изначально и поправить.
Или второй случай, Вы изменили немного текст, для того, что бы повысить релевантность страницы и хотите посмотреть обновилась страница на которой внесли изменения или нет. Проверить можно с помощью страницы, которая находится в кэше, для этого ищем данную страницу и смотрим на результат.
Так же бывает ситуация, когда сайт не доступен, по той или иной причине, а вам необходимо на него зайти. В этом случае может помочь копия страницы которую можно найти ниже перечисленными способами.
В общем я думаю, стало ясно, что пользоваться кэшем страниц нужно и полезно.
К содержанию ↑Как найти страницу в кэше Google, Yandex
Для начала давайте рассмотрим как искать в поисковой системе Google.
Способ №1.
Вы заходите на страницу поисковой системы и прописываете адрес страницы которую хотите найти и посмотреть копию. Я возьму для примера наш сайт:
loleknbolek.com
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим поисковую выдачу, где отображается страница которую вы искали. Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Поисковая выдача Google
Способ №2.
Способ можно назвать полуавтоматическим, так как необходимо скопировать адрес, что находится ниже и вместо site.ru подставить домен своего сайта. В результате Вы получите туже самую копию страницы.
http://webcache.googleusercontent.com/search?q=cache:site.ru
Способ №3.
Можно просматривать кэш с помощью плагинов для браузеров или онлайн сервисов. Я использую для этих целей RDS bar.
Кэш страницы с помощью плагина RDS barЗдесь можно посмотреть когда последний раз заходил робот на ресурс, соответственно и копия страницы будет за это число.
Теперь рассмотрим как искать кэш в поисковой системе Яндекс.
Способ №1.
Способ такой же как и для системы Google. Заходим на страницу поисковой системы и прописываете адрес страницы которую хотите найти и посмотреть копию. Снова возьму для примера наш сайт и пропишу:
url:loleknbolek.com
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим поисковую выдачу, где отображается страница которую вы искали. Смотрим на сниппет и там де URL адрес с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Поисковая выдача ЯндексСпособ №2.
Используем дополнительные плагины для браузеров. Читайте немного выше всё так же как и для Google.
Если страница не находится в индексе поисковой системы, то большая вероятность того, что ее нету и в кэше. Если страница была ранее в индексе, то возможно она сохранилась в нем.
К содержанию ↑Как очистить кэш в Yandex, Google
Бывает необходимо убрать страницу из кэша Яндекса или Гугла или вообще скрыть страницу которая ранее индексировалась и кешировалась от посторонних глаз. Для этого необходимо дождаться пока поисковая система сама выкинет данную страницу естественным путем если Вы ее предварительно удалили. Можно запретить индексировать страницу в файле Robots.txt или использовать тег:
<meta NAME=”ROBOTS” content=”noarchive”>
Только смотрите аккуратно с тегом, не поставьте его в общий шаблон сайта ибо будет запрет на кэширование всего сайта. Для этих целей лучше всего используйте дополнительные плагины или программистов которые ранее занимались такой работой.
Теперь давайте посмотрим как средствами поисковой системы Google и Яндекс можно очистить кэш (очистить, удалить страницу).
Очистить кэш страницы в Google
Поисковая система Google к этому вопросу подошла с правильной стороны и создала такой инструмент как «Удалить URL-адреса» в Webmaster Tools. Что бы им воспользоваться необходимо зайти в инструменты вебмастера по адресу:
www.google.com/webmasters/
и найти там пункт «Индекс Google». Далее ищем пункт «Удалить URL-адреса» и кликаем по нему. В итоге получаем вот такую картину:
 Очистить кэш страницы в Google Webmaster
Очистить кэш страницы в Google WebmasterДля того, что бы очистить кеш или удалить полностью страницу (а так же можно сразу удалить и очистить кэш вместе), необходимо нажать на кнопку «Временно скрыть» и ввести url адрес страницы которую необходимо очистить и нажать кнопку «Продолжить«.
Очистить кеш в Google ToolsТеперь в данном окне при нажатии на список «Тип запроса» можно увидеть несколько способов удаления и очистки как страницы с индекса гугла так и очистки кєша.
- Если Вам необходимо полностью удалить страницу и cache, то используем первый способ.
- Если необходимо просто очистить его, то используем второй способ. Как правило для нашего примера нужно использовать именно его. Страница остается в индексе, но кэш удаляется и при следующем приходе робота, она снова появится там.
- Если необходимо временно скрыть, то используем третий способ. Используется в том случае когда не успевают наполнятся страницы качественным контентом. В данном случае скрыть ее на некоторое время будет лучше.
Как только выбираете один из способов, в данном случае 2й, нажимаем на кнопку «Отправить запрос«.
Удаление из cache google страницыПосле нажатия получаем страницу, где можно увидеть, что данная страница добавлена на удаление из кэша и находится в статуже «Ожидание«. Теперь остается только ждать. Как правило данная процедура занимает от нескольких минут до нескольких часов.
Если Вы не правильно указали страницу и хотите сделать отмену, то можно нажать на кнопку «Отмена«.
Страница со статусом на удалениеПосле того как вы через некоторое время зайдете в инструмент «Удалить URL-адреса», можно будет увидеть статус «Выполнено». Это означает, что робот Гугл зашел на страницу и очистил ее историю.
Очистить (удалить) страницу в Yandex
У поисковой системы Яндекс есть похожий инструмент в инструментах для вебмастеров, но здесь есть одно «НО». Очистки кэша как такового нету, можно целиком удалить страницу из индекса ПС и при этом удалится вся ее история.
Для того, что бы воспользоваться данным инструментом необходимо зайти в Yandex webmaster по ссылке:
webmaster.yandex.ua/delurl.xml
и в строку ввести необходимый урл.
Удаление страницы из индекса ЯндексПоисковая система исключит данный адрес через некоторое время «АП». Как правило у Яндекса на это уходит пару ней, поэтому необходимо будет подождать.
Если у Вас есть вопросы задавайте их в комментариях, мы всегда на связи!
loleknbolek.com
Кэш интернета, или старые сайты, которых уже нет
Вопщем щас нашел у себя компакт 2001 года…Вспомнилось былое….
Захотелось зайти на сайт, который меня когда-то вдохновлял, а его уж нет
Вроде бы слышал краем уха про такой сервис…..
Tenoch
31 October 2010
Кэш интернета, или старые сайты, которых уже нет
вот деревня….
Tenoch
забей, новая парнуха ничуть не хуже!
Бли, была где-то ссылка, не найду теперь…. Тут даже на ФФ-клаб 2005 заходили
Tenoch
что за сайт?
youporn вроде работает ….
-1
Сенькс
А есть чо еще или это один такой сайт в своем роде?
-Alexx-
Еще раз списибо, т.к. нашел именно то, что искал
Tenoch
вроде он единственный
пишут, что его материалами даже в суде пользовались, типа такая-то инфа на сайте была
ffclub.ru